Public Cloud Is The Apex Predator Of The Internet - CDNs Need To Evolve To Stay Alive

Aug 23, 2018

CDNs have been an important cornerstone of Internet infrastructure for the past two decades. By storing and serving popular static content (video, pictures, static web code) from close proximity Points Of Presence (POPs) to users around the world, CDNs have made the Internet usable by de-centralizing and distributing some aspects of the highly centralized architecture of the Internet and the applications that run on it.
The web has of course not stayed static. Web content has become increasingly dynamic, as users expect instant and personalized experiences while using any kind of web or mobile application or service. Delivering personalized content to users requires that significant parts of the content shown by the web application or sites are dynamically assembled - just in time - by looking up things like the user's preferences, history, interests, social connections etc. While we stare into our screens and jump from one click to the next, there's a complex ballet conducted behind the scenes where a co-ordinated dance of services do things like look up databases to fetch your data, analyze the data to extract insight to recommend what song to listen to, what movie to watch or what to buy.


CDNs unfortunately seem to be getting smaller and smaller parts to perform in this dynamic ballet. Since CDNs can't handle most types of dynamic content (i.e anything that involves a look up of data or state from a database or a key/value store), they essentially act as bumps on the wire that forward the request to the origin where code and databases work together to perform the numerous lookups, transformations, aggregations and code generation that power modern web applications. (authors note - it is another matter that CDNs have been forced to focus on areas like web security, application firewalls, DDOS protection etc to stay relevant and rightly so. It is analogous to an over the hill ballet dancer now moonlighting as the usher or bouncer at the theater because they are not important to the show anymore)
So why can't CDNs handle dynamic content?

The answer to that is dynamic content requires the storage and manipulation of persistent state (data) at the edge. Most web applications need to store the data that users create or manipulate them somewhere. This somewhere is usually a database like MySQL or Postgres or Oracle. Sometimes they are NoSQL databases like MongoDB or Cassandra, and other times they are cloud databases like Google Big Table or Amazon's DynamoDB. Almost all these databases centralize the web applications data i.e. they put it all in one giant pile in one of their regions or data center locations and every single request to create, lookup or change that data means that your web application has to send a call to that database in that one location where its stored and processed by the database.
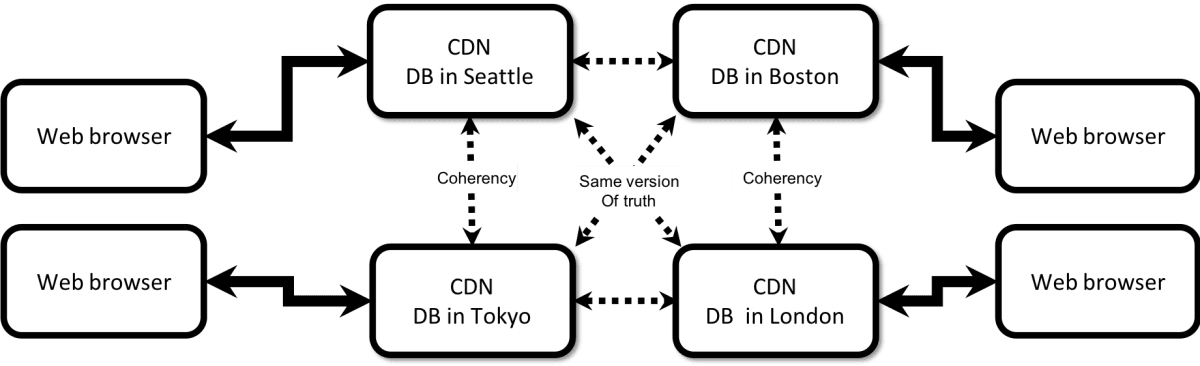
Now CDN's can't help here because they cannot cache the contents of the database on their POPs since this data changes very frequently. CDNs run into a classic old distributed systems problem called cache coherency, i.e. keeping a local copy of the data in sync with changes that might be happening elsewhere.
Now there are lots of viable ways to address coherency and certainly using an eventually consistent (or never consistent) database will work for some situations (lots of reading with low frequency of update or that it doesn't matter if the data differs slightly between two copies of the data) but they fall short in situations where a lot of data is written or changed frequently. Almost all these approaches are designed to scale a database out within a datacenter and not across data centers over the WAN or internet because WAN and internet latency is high and network routing is unstable and unpredictable.
CDNs have a very different architecture - for one they are inherently a distributed infrastructure where the CDN service stitches together hundreds of locations into one content acceleration service. Users access their data from anywhere and the CDN secretly serves the data from the POP or location closest to the end user. This means that they don't run in one location - they run in hundreds of locations all at once. Therefore conventional databases don't work to solve the dynamic content look up and generation problem since they only run in one location (and CDNs run on many) and they need a very different and special kind of database. One that is designed to run across all the POPs or edge locations all at once and somehow keep all the copies of the data in sync as it changes across all these edge locations, allowing a user to access or change data anywhere, and the location closest to that user can handle the data operation.
Technically speaking we are describing what is called a distributed, multi master and multi homing system that can work as one logical database across at-least a few hundred locations (ideally across thousands but that is for another blog post in the future) while keeping hundreds or thousands of copies of the same data on different servers in sync with each other, as fast as possible and while providing adequate consistency guarantees of the state of the data. Consistency means resolving what data operations happened (create, update, replace, delete), in what order, by whom and then somehow, every copy of the database arriving at one single version of truth after syncing their latest updates with each other.
As an example, such a mythical database would let a user in in Tokyo change a particular item in the database and it would automatically propagate the change to a hundred other locations while handling any situations where someone else (such as say in Boston) might have changed the same exact item to something different (while the user in Tokyo was also changing it) and doing this sync as fast as the network latency between the two locations will let it.


In short, this kind of a mythical database doesn't exist* and therefore CDNs can't handle dynamic content that involves looking up state.
The path forward for CDNs
3rd party independent CDN vendors are confronting an existential threat - public cloud providers are now integrating and delivering CDN capabilities with their own offerings. Cloud providers have a distinct advantage as the origin servers (web server, application logic, database etc) are already running


on their clouds (albeit in a centralized fashion and in one location chosen by the customer) and therefore providing a CDN at the edge is a simple extension for them. More worrying is that AWS for one, already has the ability to run simple apps as serverless functions at the edge on its CDNs with lambda on Cloud Front. If a customer is willing to roll up her sleeves, has a million dollars or more to experiment with, and is ready to hack at it for six months with a few senior database engineers hired from places like Facebook or Google (hence the million dollars), she might even be able to roll her own dynamic 'content at the edge' solution using AWS DynamoDB's global tables to get some shared data state replicated between regions (albeit limited to 5 regions which is the maximum number of regions supported by global tables - not particularly useful as a data base for CDNs that serve hundreds of global locations).
But CDN vendors have their own strategic advantage - deep capillary networks already in place unlike cloud vendors. Like capillary blood vessels distribute blood from the arteries to even the smallest, most distant parts of the body, CDN vendors distribute content from origin servers to the most distant and remote locations. While cloud vendors boast of having a dozen regions worldwide, typical CDN providers have hundreds of POPs around the world where they run their servers and systems for content delivery and web security. That is a huge advantage for CDN players if they can leverage their deep capillation infrastructure to push not just static content but dynamic data, server side application code to the edge. That now brings the most vital parts of the public cloud to the edge itself and creates multiple scenarios where the need to go to the public cloud to serve dynamic content are eliminated. That is revenue that used to go to the public cloud - now flowing to the CDN provider instead.


The broad global footprints of CDNs along with technology that enables data and dynamic code generation at the edge is a strategic moat for CDN operators. And if they push ahead to this new and exciting frontier of database and dynamic code on the edge - the sky is the limit for their edge clouds.






