Freeing the Database from Cages for Edge Data

Aug 20, 2019
Over the last few years the focus of enterprises has been on cloud computing, but increasingly the focus is shifting towards edge computing which provides benefit of low latency and real-time processing. But many real world edge applications require state to provide meaningful results whether that edge application is for:
- Multiplayer gaming
- Logistics, Fleet tracking & Management
- Retail Inventory Management
- Industrial automation for monitoring, predictive maintenance, etc.
- Advanced persistent threat detection against botnets & DDoS attacks
- Augmented Reality (AR) & Virtual Reality (VR) apps
- Some other IOT application
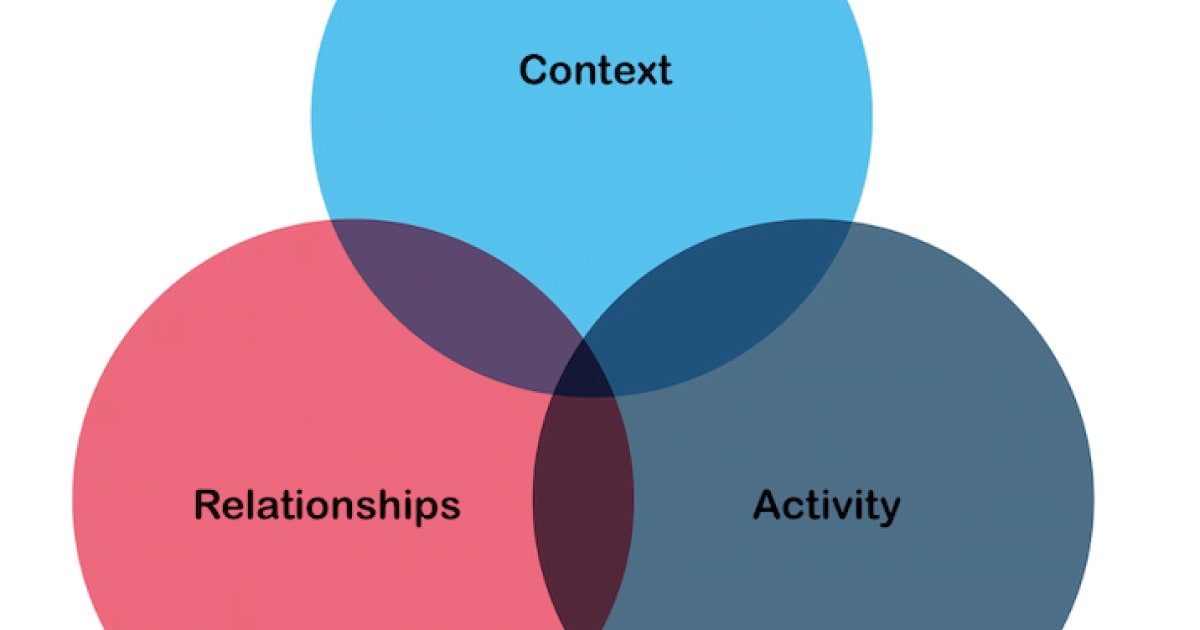
The state in an application can be broadly divided into following three categories.


Context, Relationships & Activity
Context
This state is about the environment in which the subjects of the edge application are operating under. The context also could be related to the subject behavior and management in the application like configuration, roles, rules and policies specified by the administrator. Finally context is not a fixed entity i.e., the context changes with time.


For example in a fleet tracking app, the subjects could be the vehicles, fleet, depots, etc. The context of the vehicle could be the data that describes the vehicle, vehicle specification, location of the vehicle etc. Similarly the context of the fleet could be the metadata of the fleet, number of vehicles in the fleet and other details.
Some types of context like vehicle specification may not change often, whereas other types of context like geo-location of a vehicle could change quite frequently. In between these extremes we have other types of context that may change but more gradually like policies, roles, etc.
Relationships
This state is about the relationships of the subjects in the edge application. The relationships could be
- between the subjects or
- between the subject and its context or
- between a subject past and present.
The relations provide deeper insights into the system that are not easily observable from the context alone. Using fleet tracking as an example, the relationships could provide insight into how delays with one subject (vehicle) can have a cascading impact on the other vehicles and route plans in the fleet. Or the relationship of a vehicle's current speed to its past speed could provide insights into when and why traffic violations happened. Recommender & ML engines are other areas that rely heavily on relationships.
Just like context, relations also do not necessarily need to be static and can change with time, e.g. the merchants in a credit card fraud detection app or route of a vehicle in fleet tracking app.
Activity
This state is about the current activity of the edge application. The activity could be many things like real-time sensor data, logs, commands & responses by the subject, etc. Also, it could be derived data from the current activity.
Taking fleet tracking as an example, the activity could be a vehicle’s speed, fuel level, geo location, or status. In a JAMStack app, it could be user clickstreams. The derived data could be the generated aggregations, transformations, filters and projections on the activity data.
In summary, most real-work applications involve state. What I found often useful is to look at the state requirements of a system or application via these questions to build a good mental model i.e.,
- What constitutes context for the application? How often does the context change?
- What are the various types of relationships within the system? How often does these relationships change?
- What constitutes activity and derived activity for the application?
The next important question is then how do we store, manage and process this state?
Data Models & Data Stores
Databases have been around for a long time, and each of us have some ideas about what they are - and what they can be. Basically most data stores are organized around a single data model that determines how data can be organized, stored, and manipulated.
For example, the relational data models became popular after its publication by Edgar F. Codd in 1970. This was the de-facto standard until NoSQL databases became common around 2009.
NoSQL databases use a variety of data models, with document, graph and key-values models being popular. Similarly, in domains that deal with data-in-motion event driven processing models like Complex Event Processing (CEP), Messaging (pub-sub, queues), and Stream processing became very popular. Each of these data store types have their own, unique advantages.
Let’s consider the state we talked in previous section. To briefly summarize, the state of an application can be broadly divided into 3 categories -
- Context
- Relations
- Activity
For storing and managing context state, probably the most appropriate data store is either a relational, document or key-value database. If the application requirements involve querying data, filtering, or joins then probably document or relational database is a better bet. In addition if the edge application state spans multiple regions then a document database is likely a better bet. Many document databases now also provide ACID semantics within a region.
For storing and managing relations state, the most appropriate database is a graph database. When you want a cohesive picture of your data, including the connections between subjects, graph database is the right model for it. In contrast to relational & document data stores, graph databases store data relationships as first class objects. This means fewer disconnects between your evolving schema and your actual database.
Also, the flexibility of a graph data model allows to add new nodes and relationships without expensive data migration issues. With data relationships at their center, graph databases are incredibly efficient when it comes to query speeds, even for deep and complex queries. Relationship traversals and other graph operations is a nightmare to do in relational and document databases with joins.
Similarly, for storing & managing activity state, probably the most appropriate data store is either a time series database (if activity is time series data) or a stream store (if activity is log data). Further depending on the processing requirements of the activity state, one may as well need a stateful/stateless stream processing solution.
While each of these data stores can handle well specific types of state created by an application they also create a very big problem. Each of these data stores create a technical silo i.e., a data store with boundaries between them that are both physical (because the data is stored in different places) and conceptual (because the data is stored in fundamentally different forms).
Until recently, this forced a difficult choice:
- Choose one datastore model (i.e., relational / key-value/ document / graph / stream model) and work within the constraints of the datastore by moving the complexity to the developer.
- Alternatively, choose a few data store models and cobble them together with ETL jobs and integration code - yet again moving the complexity to the developer.
Edge complicates this further. Imagine having these cobbled systems globally across dozens of locations to process data at the edge. There should be a better way!
Another example
Consider for example (credits: https://arxiv.org/pdf/1609.07548.pdf) the health data collected from thousands of critical care patients in an Intensive Care Unit (ICU). The anonymized health data is publicly available at http://mimic.physionet.org/. It contains context state i.e., structured data such as demographics and medications; unstructured text such as doctor and nurse reports; relations state i.e., caregivers to patient relations, patient to lab relations, etc. and activity state i.e, time–series data of physiological signals such as vital signs and electrocardiogram (ECG).


Further some insights are more valuable shortly after events have happened, with the value diminishing quickly over time. So you also need a streaming platform (for receiving events) and stream processing platform (for processing events) to provide insights faster, often within milliseconds to seconds from the trigger.
Also the analytics often will cross the boundaries of a single data modality, such as correlating information from a doctor’s note against the physiological measurements collected from a particular sensor in realtime. In that case, you need another platform to run the ETLs and other data pipelines. Now imagine running and maintaining this business application across 10s and 100s of locations at the edge.
Multi-Model Database
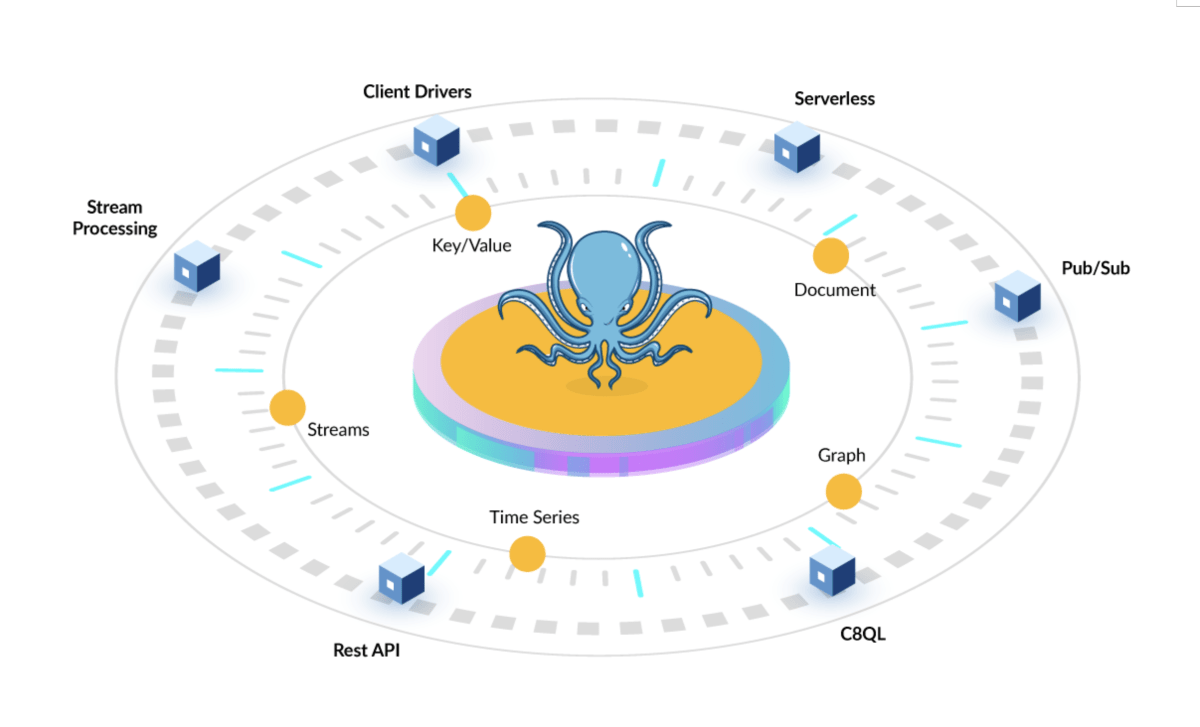
What developers and organizations really want is a way to use all their data in an integrated way, so why shouldn’t a data platform support this out of the box by natively integrating data storage, access and processing across different data models and paradigms (data-at-rest, data-in-motion). This is what I mean by freeing database from its cages.


A database that is free of cages supports multiple data models and paradigms (data-at-rest, data-in-motion) within a single, integrated backend, and provides uniform api, query and indexing capabilities. Queries are extended or combined to provide seamless query across all the supported data models and paradigms. Indexing, parsing, and processing appropriate to the data model and paradigm are included in the core database product.
So why do databases have these cages? I suppose one reason could be that most databases are tightly coupled monolithic systems collapsing the query layer , indexing layer, processing layer and storage layer into one. Same with streaming platforms which also have these same layers. Another reason could be the herd mindset (i.e., the comfort & security in staying with current status quo) which silently constrains our ability to see and question. Or maybe it is some other reason. IMO why databases have these cages does not matter much. What matters is can we free the database from these cages?
So can we free the database from these cages? I certainly think so. For example, Macrometa Fast Data platform currently supports the data models and paradigms mentioned above with more features like search to come in near future. This is certainly not the only way to free the database from cages. I am sure in next few years we will see more around this idea of freeing databases from cages as edge becomes the center.

Wrapping Up
Finally, a sales pitch :-) Macrometa provides a managed service, enabling you and your teams to easily build, deploy and run cross-region or global, data driven, multi-modal & real time apps and APIs. Give it a try with a free developer account to explore and decide for yourself.








