Macrometa & AWS Lambda - Geo Distributed Stateful Data For Serverless Functions - A Step By Step Guide

Aug 09, 2019
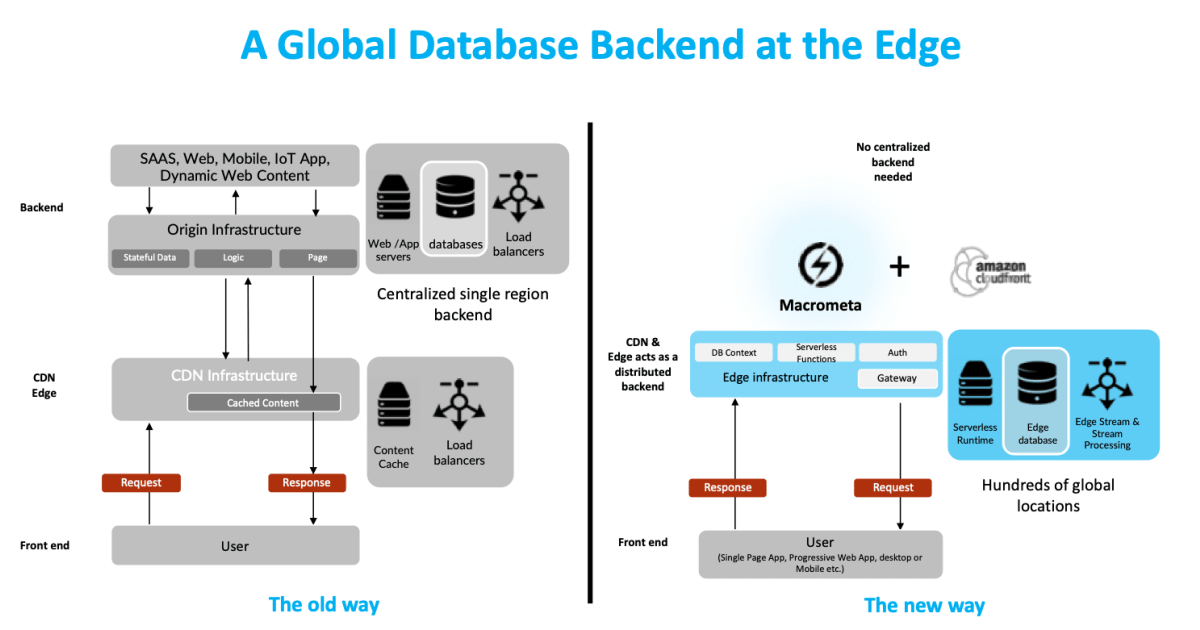
At some point in the last 12 months, something historic happened quietly and right under everyones' noses. Without much fanfare, the center of gravity for cloud computing moved from the centralized databases and compute in giant hyper-scale data-centers to the edge of the network where CDNs live. This tectonic shift changes the way you (dear developer) will build applications, APIs and all things programmable in the months, years and decades to come.
The shift started with AWS introducing a radical new way to build applications with functions as a service 2 years ago. Dubbed "lambdas", AWS' serverless functions let you create functions of code that are spun up on demand in response to events in the real world - or in other adjacent systems. Without the burden of any infrastructure to operate or manage, Lambdas let anyone create web scale backends that scale elastically to meet demand with a powerful cost model - you only pay for the resources your functions consume while they run. As great as lambdas are they still sat in a single AWS cloud region and that meant any calls to your lambdas had to travel across the internet, over hundreds of miles, thousands of milliseconds of time to get to the runtime to execute the function. That coupled with the fact that your lambdas might be cold (no running instances to route the request to) meant that they were slow for many real time use cases. AWS solved the first problem by introducing Lambda @ edge - a node.js lambda engine that serves JavaScript functions at 100s of globally distributed locations around the world. With Lambda @ edge your requests could now go to the closest AWS edge and be served by a JavaScript function in milliseconds. Problem solved? Almost. The cold start problems remained.
Serverless functions and workers at the edge - exciting possibilities
There's still one giant problem waiting to be solved for the next era of edge cloud computing to really take off. While we've moved compute to the edge, the data is still sitting hundreds of miles and thousands of milliseconds away in lonely, centralized databases in a single cloud region and not at the edge.
Now imagine if like Lambda @edge, CloudFlare Workers and Fastly Lucet/Terranium, you had a database that was globally geo-distributed and ran in 100s of locations worldwide and delivered accurate, highly consistent, mutable data to your functions in real-time?
Segue into CloudFlare and Fastly
CloudFlare workers are similar to Lambda @ edge in philosophy but entirely different in design and implementation. Eschewing node.js, CloudFlare Workers instead use the V8 Javascript engine (the same V8 that runs in your Chrome browser but extensively reengineered to run at the CDN edge) to execute JavaScript functions inside their lightning fast edge locations spread around the world. Using their GUI Worker developer tools or the command line based wrangler tool, you can write, package and deploy a worker to all their 200+ locations in seconds and have your own global, geo-distributed workers responding to requests at insanely low latencies for fractions of a penny per invocation.
Also, the awesome folks at Fastly have their own vision and implementation of serverless workers with Lucet and Terrarium. Lucet is incredibly exciting - it can fire up a worker from (or isolate from) the cold in under 15 microseconds (that's micro not milli). I've chosen not to write about WASM in this post - but will share thoughts on WASM in a separate post.
Macrometa and AWS Lambda @ edge - a global stateful data layer for serverless functions in the cloud and at the edge
Macrometa is an ultra scale, geo-distributed serverless database platform. Put simply, its a new kind of database that doesn't run in just one cloud region or data center - it runs across hundreds just like the serverless runtimes provided by Lambda @ edge, CloudFlare Workers and Fastly Lucet/Terrarium. But like conventional databases it provides strong consistency guarantees, a query language and a modern interface (multi model - K/V, JSON DocDB, GraphDB, Stream, pub/sub and more in one interface) and serverless API for working with it. Unlike previous attempts to build these databases that tradeoff consistency for speed, Macrometa provides a rich set of consistency primitives to ensure that data is not just mutable at the edge but is also globally and shared with accuracy and low latencies.


By coupling the Macrometa serverless database with your functions on any of these edge computing runtimes, developers can now write apps, APIs and all kinds of incredible things that automatically run globally in seconds across 100s of locations serving data and compute instantly - something that previously only the giant web scale tech companies like Google, Facebook could do.
To give you a taste of the awesome power that the combination of these technologies provide - let's switch gears and build a stateful geo distributed AWS Lambda @ edge function that runs globally and queries data from the Macrometa database edge location closest to where the function is running.
Writing a global stateful Lambda function in 5 easy steps
In this example we will serve a globally geo-distributed address book that has a bunch (about 500) names, email addresses and zip codes that are stored in the Macrometa global database across 25 global locations worldwide.
use this link to see it in action - https://4uiu9z43qj.execute-api.us-west-1.amazonaws.com/default/addressbookFunc
How it works
When your client (mobile app or web browser) calls the URL of the Lambda @ edge function, DNS will resolve the address using global latency based routing to send the request to the closest Lambda @ edge PoP (a regional/local datacenter where the function is stored and runs). For context there are about 180 PoPs that AWS provides which means that users are never more than 25ms away from the vast majority of them. When the https request is received, the Lambda @ edge function is invoked and it makes a call to the Macrometa database using a light weight graphQL end point (we call it RESTQL - you can learn more about it by reading about our query language C8QL and how to expose it as a graphQL end point programmatically or via the Macrometa web console).
Overview of the steps
- Step 0 - Get a free Macrometa developer account at https://www.macrometa.co/start


- Step 1 - Create a global fabric and data collection in Macrometa
- Log in using your credentials
- Once on the main console page, click on collections and add collections
- Click on create collection and use the dialog to provide details
- Skip the key - we will use an autogenerated one
- Give the collection a name - lets call it addresses and click save
- Step 2 - Put some data in your global collection
- Click on Query on main console page
- In the query editor copy paste the address book data:
- Open this pastebin link - https://pastebin.com/5qSmBBgW
- Copy the query and paste in the Macrometa query window
- Click on Execute to run the query and insert the data
- You can click on the collection / Addresses and see that the data has been inserted
- Cool feature - on the main console click the top link global fabric and click on one of the map pins - by clicking on the >> you can open a direct console connection to that data center and use the console to browse data and perform operations on that location. You can click collections on a console in a different datacenter and see that the data has replicated.
- Step 3 - Write a query to enumerate it and expose it as a geo-distributed RESTful end point
- Open the Query and click new
- Copy / paste or type the following
- for docs in addresses return docs
- execute it and it will enumerate all the docs in the addresses collection
- Click "Save as" and give it a name in the dialog - call it showAddresses
- Click on queries and you should see it at the top of the list - click the Play button to run/test it
- Now comes the magical part. When you saved the query, Macrometa automatically turned the function into a globally distributed RESTful end point
- Click on Support in the main console, in the API viewer scroll down to the RESTQL section
- Find the API end point for "Execute restql by name" (the second one under RESTQL) and click on it and then click "Try it out"
- Provide your tenant id (you got this when you signed up)
- Provide your fabric name (_system if you didn't create a new one - the default is _system)
- Provide the query name - showAddresses
- Now click execute and you should see the API execute and its response displayed below
- There's a section which shows you the curl command - we're going to need this in the next section
- You can copy past the curl command on your command line and run it if you have curl installed.
- IMPORTANT - copy the url after POST between the quotes
- it looks like this (copy the highlighted part from the API explorer) - "https://<host>macrometa.io/_tenant/<tenantname>/_fabric/fabricname/restql/execute/showAddresses"</tenantname></host>
- Paste in your favorite text editor and change the tenant name and fabricname to your tenant name and the fabric you created before
- Now copy the part after the bearer (this is your authentication token)
- It looks like this (copy the part highlighted in yellow from the API explorer in the UI console under support)-
"Authorization: bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE1NjY2OTEyNTYsImlhdCI6MS41NjQwOTkyNTYwMzQyMTIyZSs2LCJpc3MiNOTAREALTKEN3VzZXJuYW1lIjoicm9vdCIsInRlbmFudCI6Il9tbSJ9.GC5wZG0Ng6AM0wEna1un7-8G0PY6Q7ROnzCnxxrtxMA=" - Copy the part AFTER the bearer till the end of the string and paste in your favorite editor
- Step 4 - Integrating the Database RESTful API with the Lambda functions -
- Assuming you already have a AWS account, create a new Lambda function and make sure it is placed to run at US-EAST-1


- Once you get to the code editor, copy and paste the following code from pastebin
- Open https://pastebin.com/yvdTKWWu
- Now carefully copy the url from your text editor and paste the URL you copied from the Macrometa Console where it says host and path (make sure you don't inadvertently add or remove anything while copy pasting).
- Change the tenant name to your tenant name
- Next copy the authentication token and paste it inside the quotes starting from bearer in the headers section where it says 'Authorization' :
- Click save and test and you should see it run inside the console and retrieve data from the nearest Macrometa databased edge location
- Step 5 -Adding
- Assuming you already have a AWS account, create a new Lambda function and make sure its placed to run at US-EAST- virginia
- It's Showtime - if you've not missed a step or made any typing mistakes so far, your Lambda will now deploy and automatically pull data from the closest Macrometa Fast Data PoP.
- Use the API end point provided by the AWS gateway and test to see if your Lambda fetches data from on the 25 global data Pops closest to it that Macrometa provides.
Note that this lambda is not geo distributed yet - that will need you to setup a cloudfront distribution which I will cover in a separate post. But the steps to do that are easy and you can find plenty of examples on google for that if you want to try it out now.
So there you have it - a completely serverless, stateful, global, geo-distributed API end point that will serve dynamically queried database responses in milliseconds all around the world
fin!








